Decomposing a Monolith with APA (and a Lot of AI)
Another weekend, another thing I find beautiful enough to write down.
I've written before about Android Plugin Architecture (APA) — it's been my long-running passion. Most of my advocacy has been theoretical: here's why you should structure large apps this way, here's the build and modularization payoff, here's what it could look like.
This weekend I stopped writing about it and just did it. To a real, large, production app monolith. By my AI agent that I call "Frankenbot".
I'm not done. But what I have working is enough that I had to share.
The Starting Point
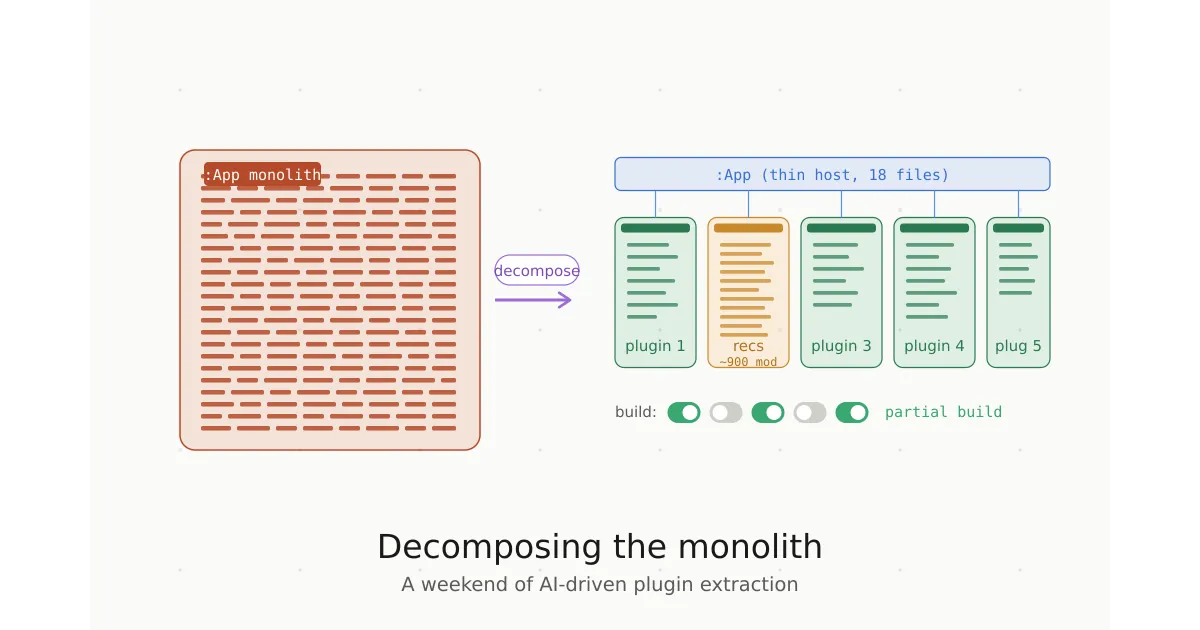
The app module — the top-level :App Gradle module that ties everything together — was the textbook monolith. On the main branch:
- 414 Kotlin files
- 223 XML layouts
- A dependency graph that pulled in all 1300+ app-related modules of the app
That's a lot of code sitting in the one module that every build has to compile, regardless of what you're working on. It's the worst possible place for code to live from a build-performance standpoint, because nothing downstream can be cached when it changes — and almost everything depends on it.
The Goal: Five Plugins, One Host
The app has five bottom navigation destinations — think of them as the five top-level features users actually interact with. The hypothesis was simple:
Each bottom nav destination should be its own plugin. The :App module should be a thin host that wires them together.If that works, three things become possible:
- Partial builds — build the app with only 1, 2, 3, 4, or all 5 plugins. Iterating on a single feature means compiling a fraction of the code.
- Parallel CI — affected-module logic can determine which plugins changed and build/test only those.
- Splittable instrumentation tests — Espresso tests can be partitioned across plugins using dynamic source sets, enabling parallel test execution.
Brute-Force AI Decomposition
Decomposing a monolith of this size by hand is the kind of project that takes a small team a quarter. I wanted to see how far I could get over a weekend with AI doing the bulk of the mechanical work.
The approach: I let an AI agent loose on the codebase with my governing rule (apa-modularization.md), then babysat it at roughly hourly intervals to course-correct. Each correction sharpened the rule. The rule got better, the agent got more autonomous, the corrections got rarer.
This was not a hands-off process. There were stretches where I had to get deeply involved — untangling circular dependencies the AI couldn't reason about cleanly, making judgment calls about which plugin a shared file actually belonged to, fixing the cases where it confidently moved something to the wrong place. But for the bulk of the work — moving files, updating imports, threading dependencies through the right Gradle files — the AI was doing the heavy lifting.
By the end of the weekend:
- 18 files left in the original
:Appmodule betweendebug/andmain/(down from hundreds) - All of
:App's former project dependencies pushed down into the 5 plugins - The app successfully builds and runs with any subset of the 5 plugins enabled
The 18 remaining files are the genuinely cross-cutting glue. Some will go away with another pass. Some are correctly host-level. I just ran out of weekend.
What Partial Builds Actually Look Like
The payoff is that you can flip plugins on and off and the build genuinely respects that. Want to iterate on the home feed? Build with one plugin enabled. Working on something cross-feature? Build with all five.
This isn't simulated — Gradle is genuinely compiling fewer modules. The dependency graph for a "feature 1 only" build is a strict subset of the full graph. Less to compile, less to link, less to package.
For day-to-day development, this is the difference between a build feedback loop that respects how you actually work and one that punishes you for the size of code you aren't touching.
The Plugin That's Still Too Big
Honest disclosure: one of the five plugins still pulls in around 900 modules transitively. That's the core feed/recommendations surface — the heart of the app. It's expected that the highest-traffic feature has the largest dependency footprint, but 900 is more than I want.
Two things will help:
- Further pluginization. The recommendations plugin can itself be decomposed — there are clear sub-features inside it that could become their own plugins under the same architecture. Plugins of plugins, basically.
- Dependency raking. A lot of those 900 modules are almost certainly transitive dependencies that don't need to be
implementationorapiat the level they're declared. Walking the graph and demoting dependencies to the narrowest scope they actually need is mechanical work but it consistently shaves modules off the visible graph.
I'll do the rake next weekend. I'd bet a meaningful percentage of those 900 modules are demotable.
The CI Implication
This is where APA stops being a developer-experience win and starts being a CI win.
The expensive steps in any large Android pipeline are:
assembleDebugfor the full appassembleDebugAndroidTestfor the Espresso APK- The Espresso test execution itself
Today these run unconditionally on every PR, because the app module is in the affected set of basically every change. With the monolith decomposed:
assembleDebugcan build only the plugins whose code (or transitive dependencies) changedassembleDebugAndroidTestcan do the same — and Espresso tests can be split into five buckets using dynamic source sets- Both can run in parallel across plugins
Combined with smart CI sharding (see my previous post on Dynamic Pipelines), you get a pipeline where unrelated changes don't pay for each other's compilation. A change isolated to one plugin builds and tests one plugin's worth of code.
That's the architectural payoff I keep advocating for. Modularization isn't free, but the ceiling on what you can do with a properly modular codebase is dramatically higher than what you can do with a monolith — even a well-organized one.
What's Next
A short list of things I want to do next weekend:
- Rake dependencies to lower the module count per plugin
- Speed tests — measure actual build times for 1-plugin, 3-plugin, 5-plugin builds vs. the monolith baseline
- Decompose the recommendations plugin further if the rake doesn't bring it down enough
- Wire up dynamic source sets for the Espresso test split
- Get the last 18 files out of the host module (or confirm they belong there)
Why I'm Sharing This
A few reasons:
This is the most validation I've ever had for APA as a real architecture for real apps. Theory is one thing — getting a production-scale monolith to actually build with plugin subsets is another.
It's also a data point on what AI is genuinely good for in large codebases right now. Mechanical decomposition with a governing rule is a perfect fit. The agent can hold more file-level context than I can; I can hold more architectural intent than it can. The collaboration is genuinely more than the sum of its parts when the rule is sharp.
And honestly? It's just beautiful when it works. A monolith that felt tangled beyond practical decomposition turns out to be tractable when you have the right architectural target and a tireless collaborator willing to do the file-moving. I needed to write it down before the weekend ended.
More next week.