Smarter Sharding: The Jaccard Similarity Idea
Most sharding algorithms are naive: divide N modules into chunks of size K. The problem is that modules aren't independent — they share dependencies. If module A and module B both depend on the same set of libraries, building them on different shards means those libraries get built twice. Building them on the same shard means you build A, B, and their shared dependencies exactly once.
This is where Jaccard Similarity comes in.
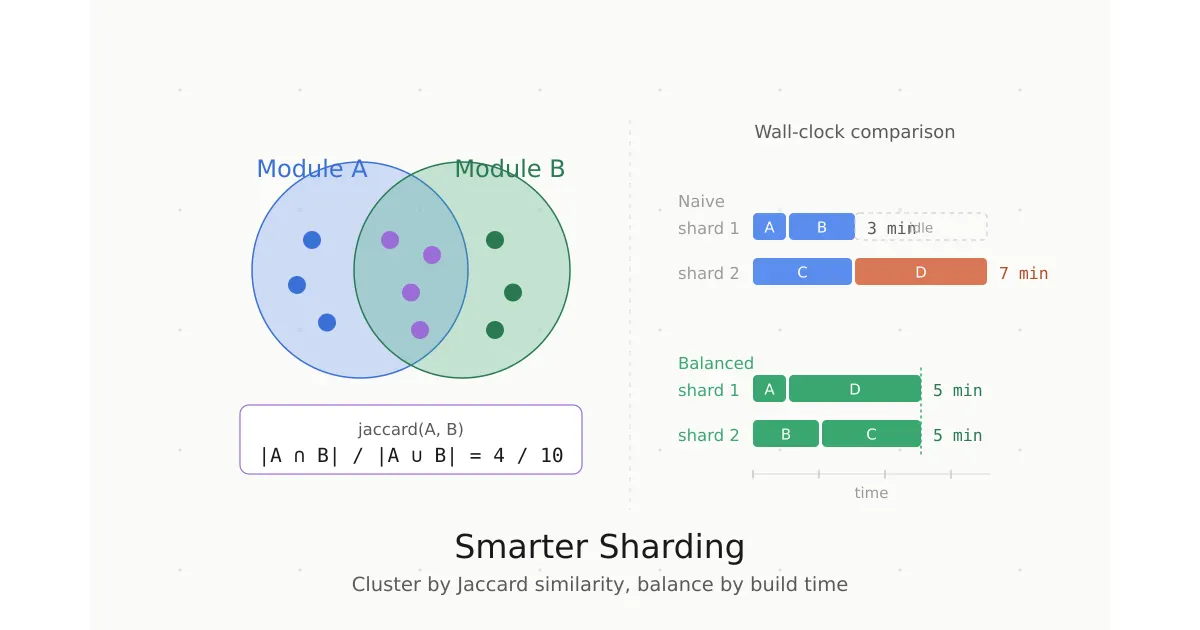
Jaccard Similarity between two sets is defined as the size of their intersection divided by the size of their union. If module A depends on {X, Y, Z} and module B depends on {X, Y, Z}, their similarity is 1.0 — they're perfect candidates to co-locate on the same shard.
The algorithm:
- Cluster modules by their dependency fingerprints using Jaccard Similarity
- Assign weights to each cluster based on historical build times
- Load balance shards by weight, not by module count
Example across 4 modules with known build times:
A: 1 min B: 2 min C: 3 min D: 4 min
Naive (2 shards): [A, B] = 3 min [C, D] = 7 min → 7 min wall clock
Balanced (2 shards): [A, D] = 5 min [B, C] = 5 min → 5 min wall clock
Dynamic Pipeline already has infrastructure for timing-based shard balancing — the binary can read a cached job-timings file to inform distribution. The Jaccard clustering layer would sit on top of that, ensuring that co-located modules share as much build graph as possible.
For a large modular repo, this isn't a micro-optimization. It's the difference between shards that finish together and shards where one runs for twice as long as the others.